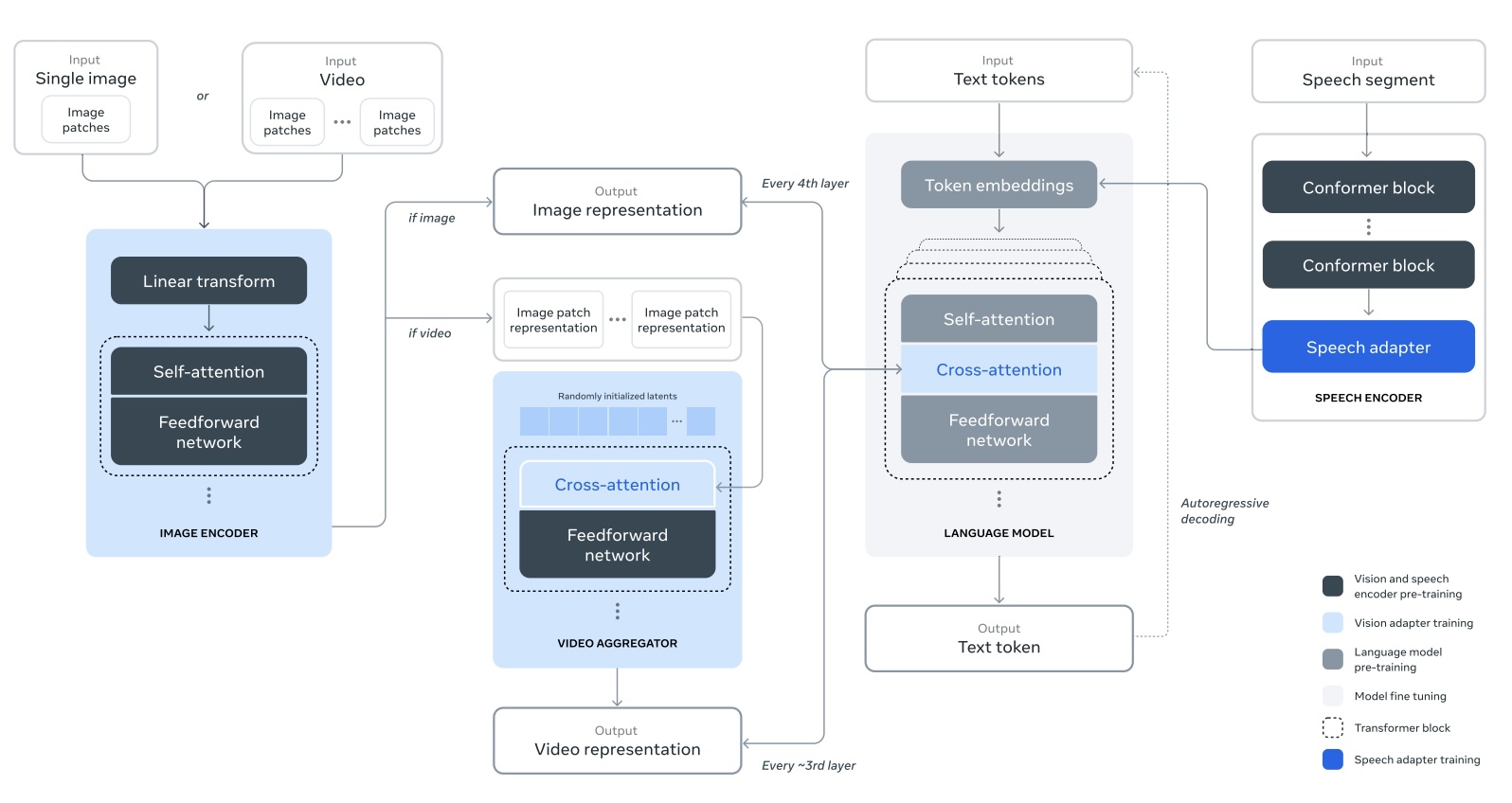
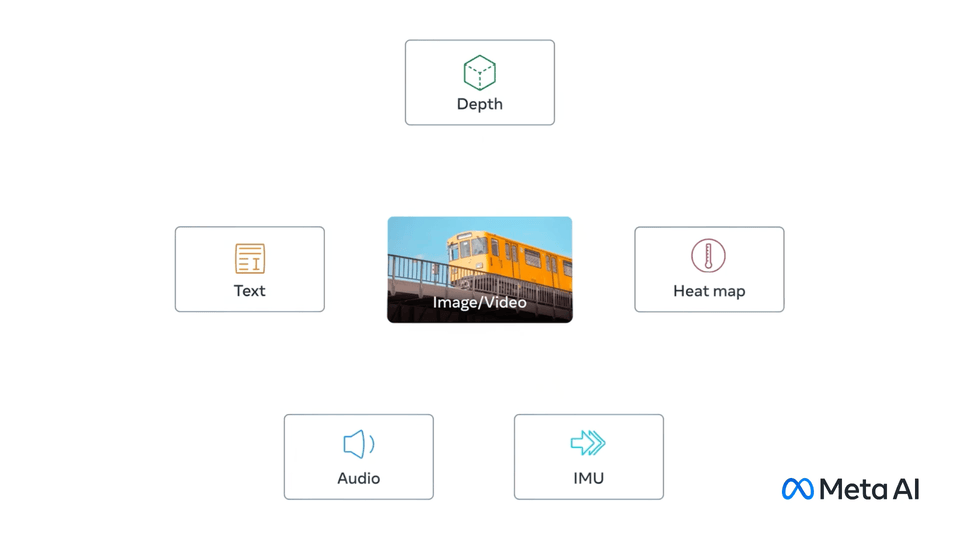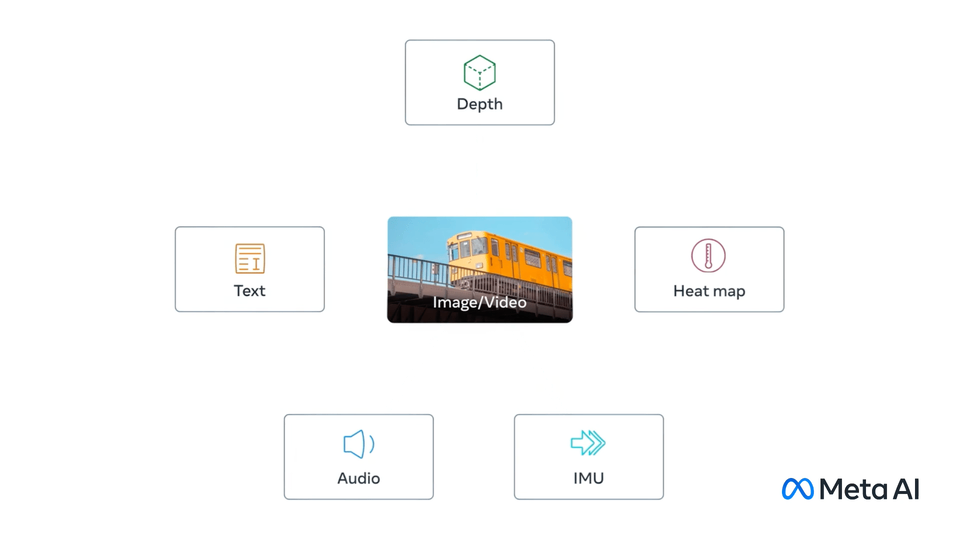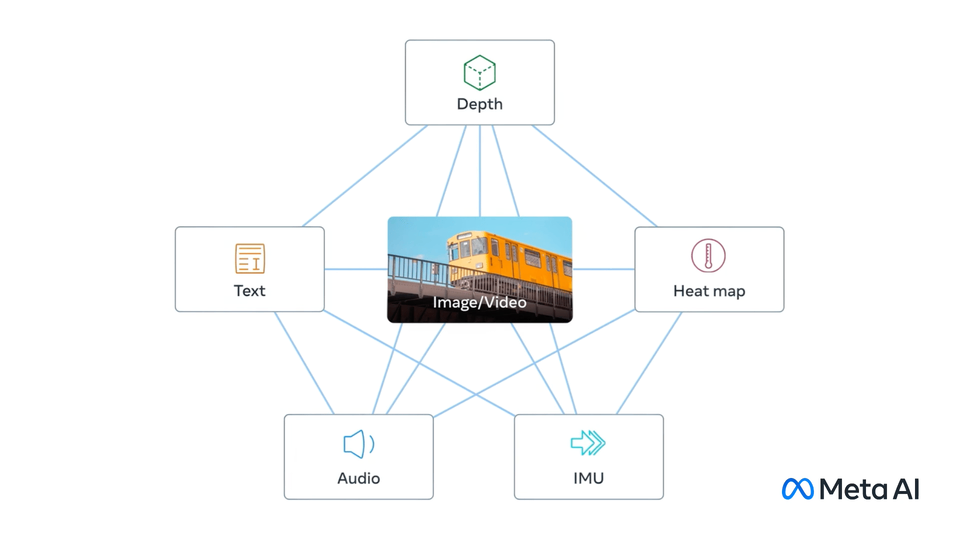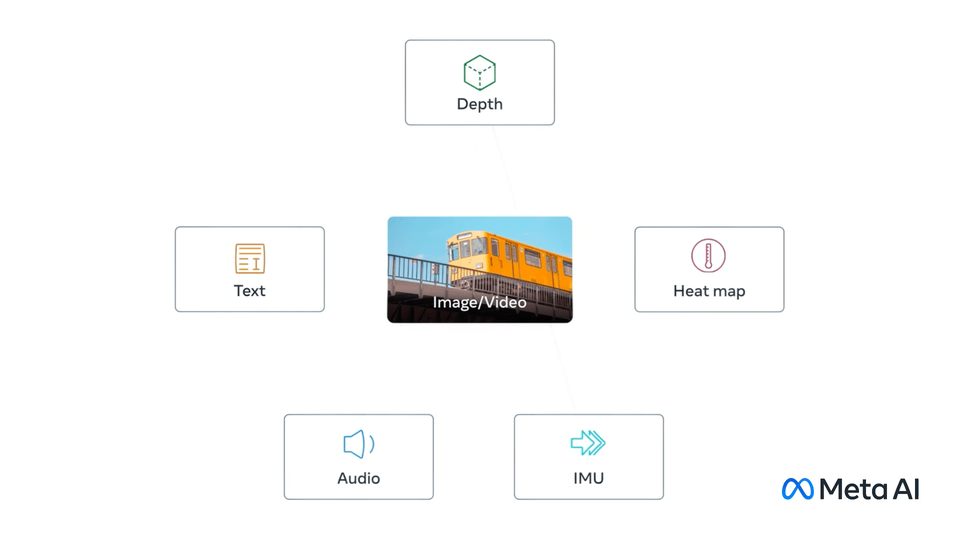
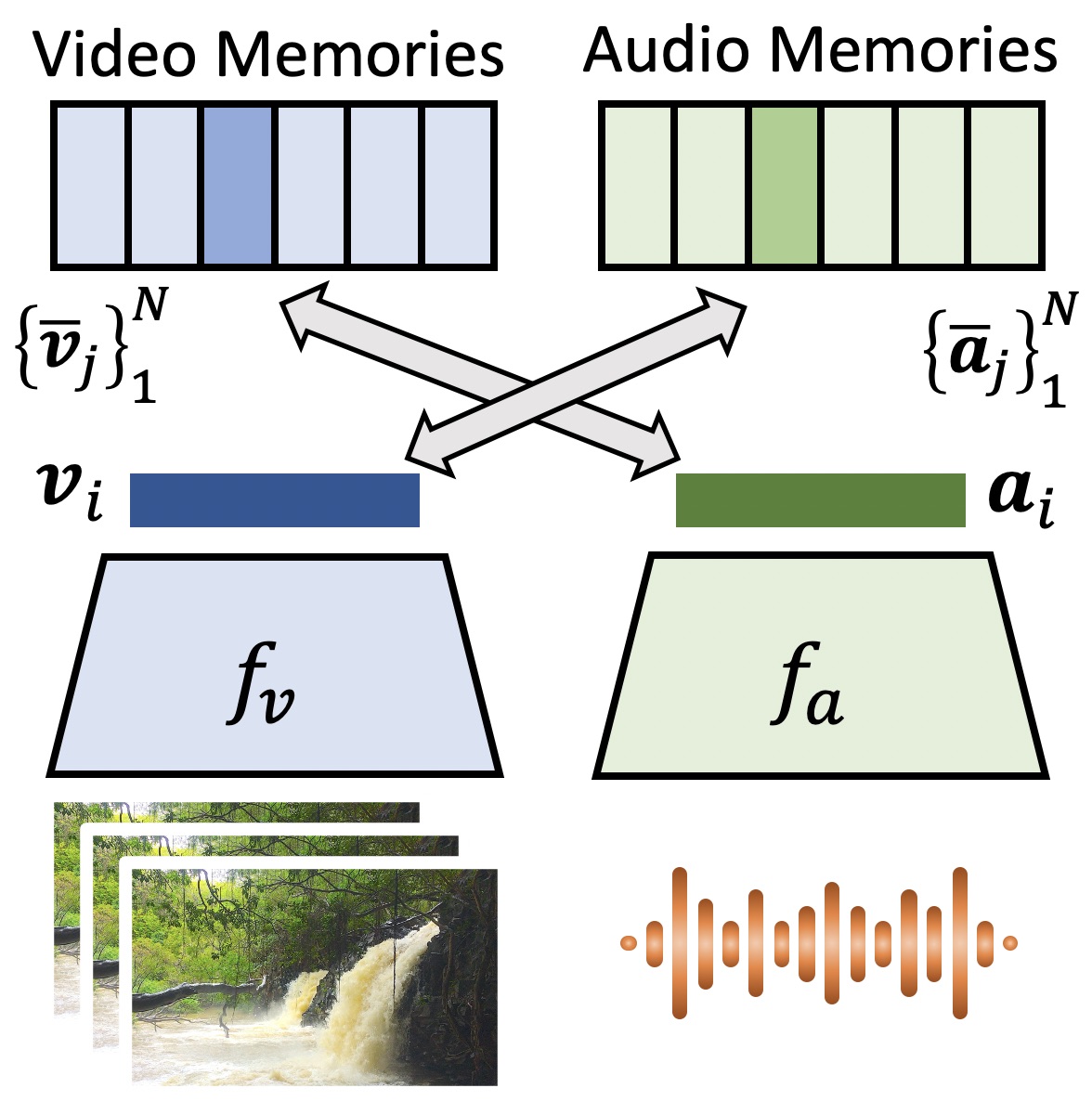
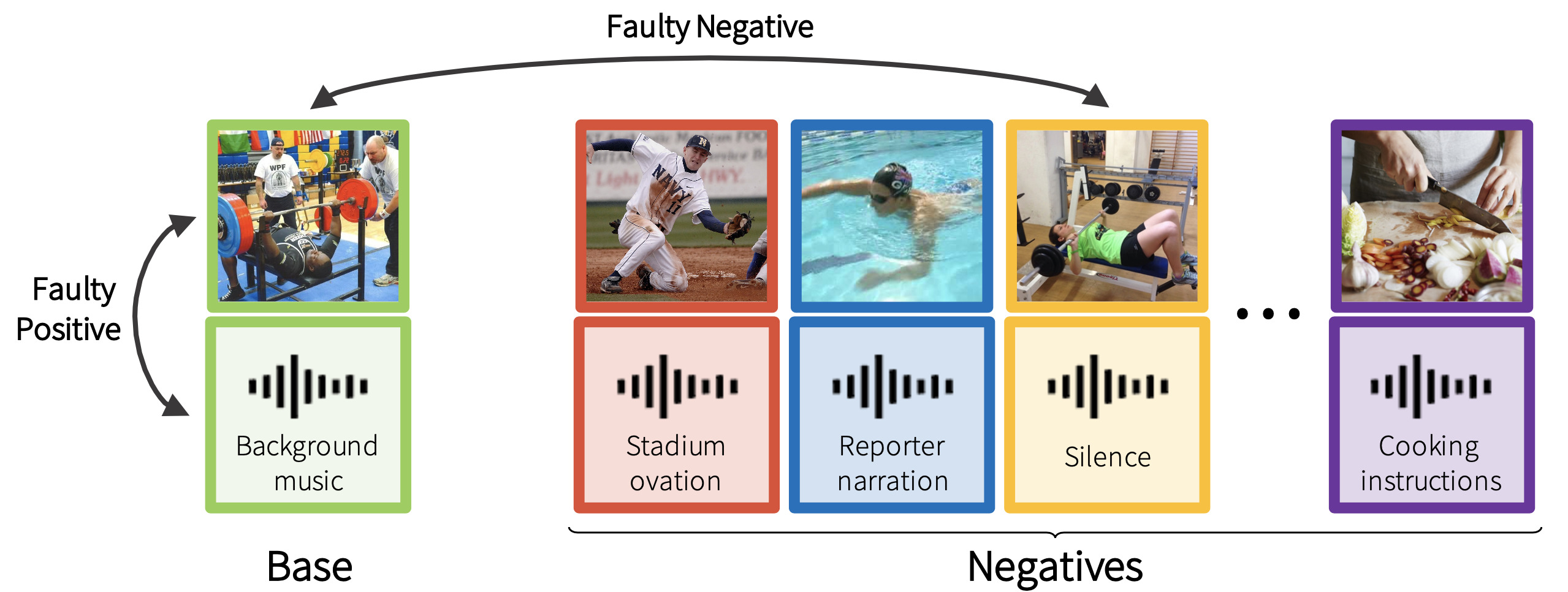
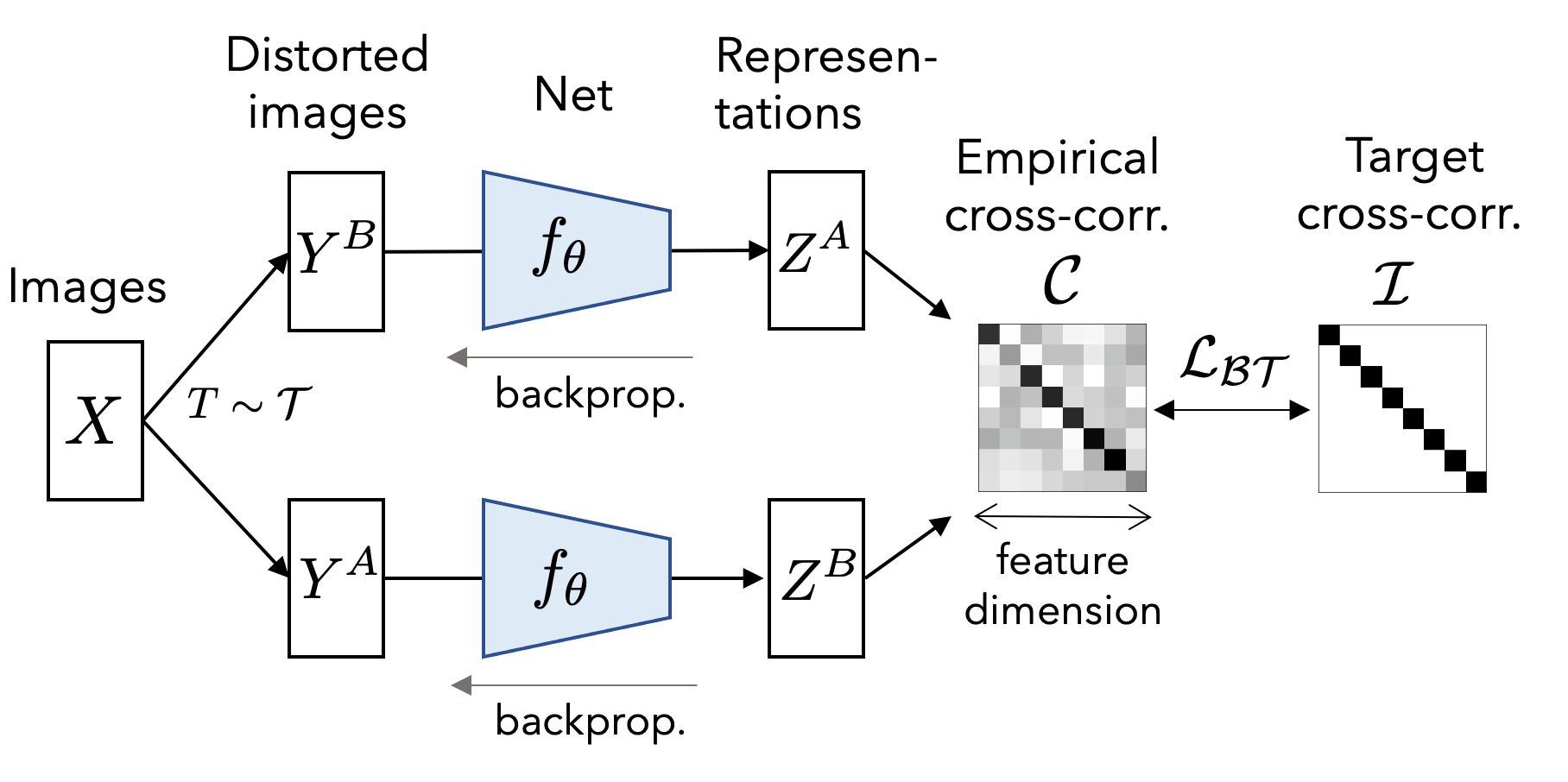
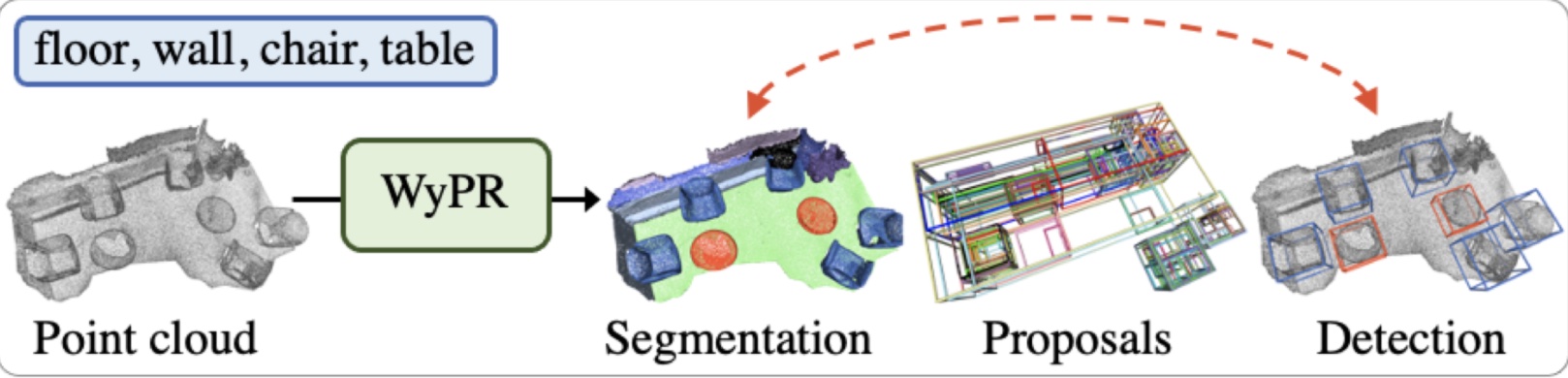
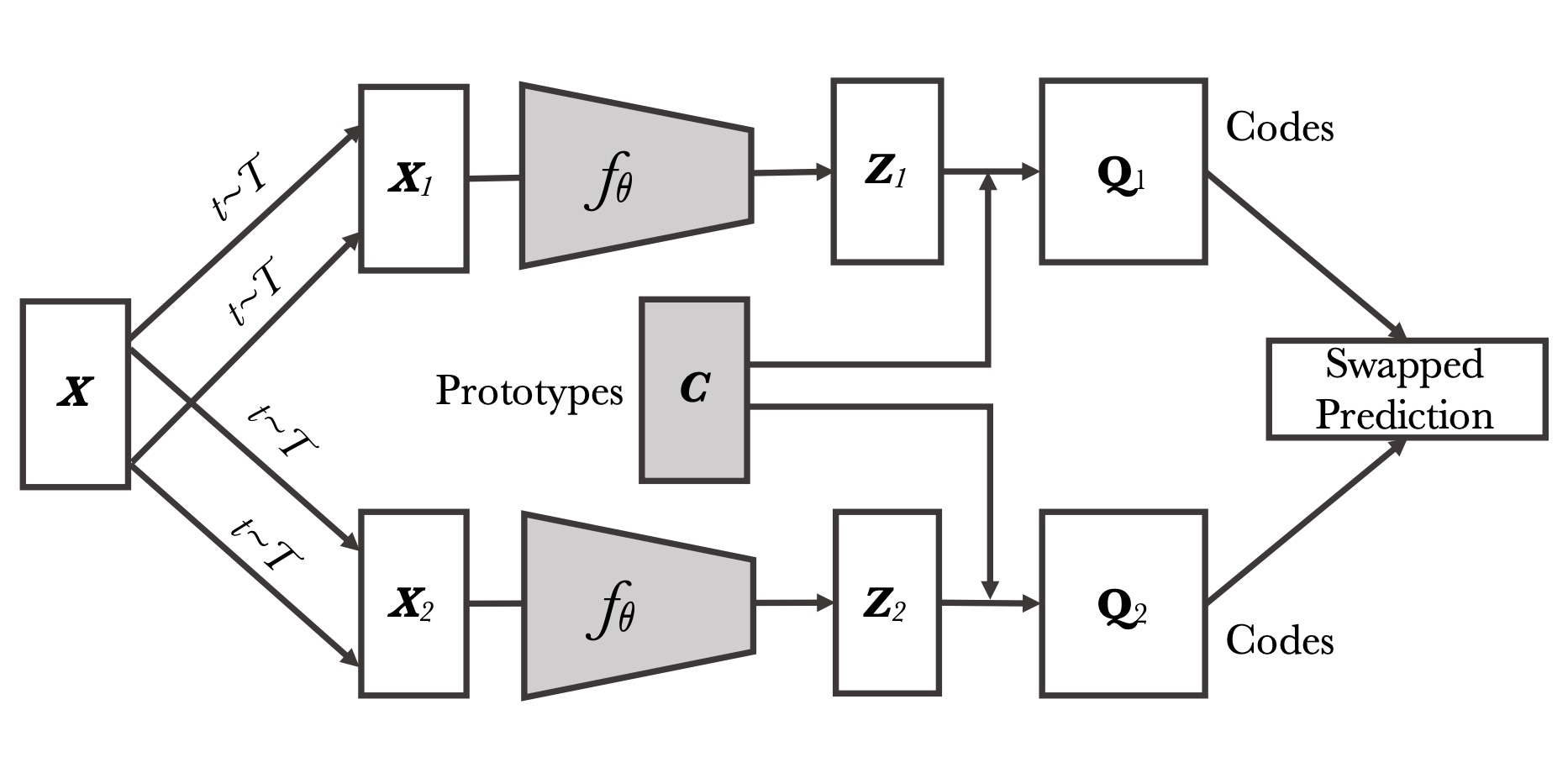
Mainly publish on video and image understanding, video and image generation, object detection/segmentation, multimodal learning, and self-supervised learning.
The Llama 3 Herd of Models
The Llama3 Team (played role of a Core Contributor for video recognition)
arxiv 2024
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Rohit Girdhar^ *,
Mannat Singh^ *,
Andrew Brown *,
Quentin Duval *,
Samaneh Azadi *,
Sai Saketh Rambhatla ,
Akbar Shah ,
Xi Yin ,
Devi Parikh ,
Ishan Misra
*
ECCV 2024
PDF
BibTeX
Powers Meta's /animate product
*Authors contributed equally
@inproceedings{emuvideo2023,
title={Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning},
author={Rohit Girdhar and Mannat Singh and Andrew Brown and Quentin Duval and Samaneh Azadi and Sai Saketh Rambhatla and Akbar Shah and Xi Yin and Devi Parikh and Ishan Misra},
inproceedings={ECCV},
year={2024},
}
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Feng Liang ,
Bichen Wu ,
Jialiang Wang ,
Licheng Yu ,
Kunpeng Li ,
Yinan Zhao ,
Ishan Misra
,
Jia-Bin Huang ,
Peizhao Zhang ,
Peter Vajda ,
Diana Marculescu
CVPR 2024
@inproceedings{liang2024flowvid,
title={FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis},
author={Feng Liang and Bichen Wuand Jialiang Wang and Licheng Yu and Kunpeng Li and Yinan Zhao and Ishan Misra and Jia-Bin Huang and Peizhao Zhang and Peter Vajda and Diana Marculescu},
booktitle={CVPR},
year={2024},
}
InstanceDiffusion: Instance-level Control for Image Generation
Xudong Wang ,
Trevor Darrell ,
Sai Saketh Rambhatla ,
Rohit Girdhar ,
Ishan Misra
CVPR 2024
Generating Illustrated Instructions
Sachit Menon ,
Ishan Misra
,
Rohit Girdhar
CVPR 2024
VideoCutLER: Surprisingly Simple Unsupervised Video Instance Segmentation
Xudong Wang ,
Ishan Misra
,
Ziyun Zheng ,
Rohit Girdhar ,
Trevor Darrell
CVPR 2024
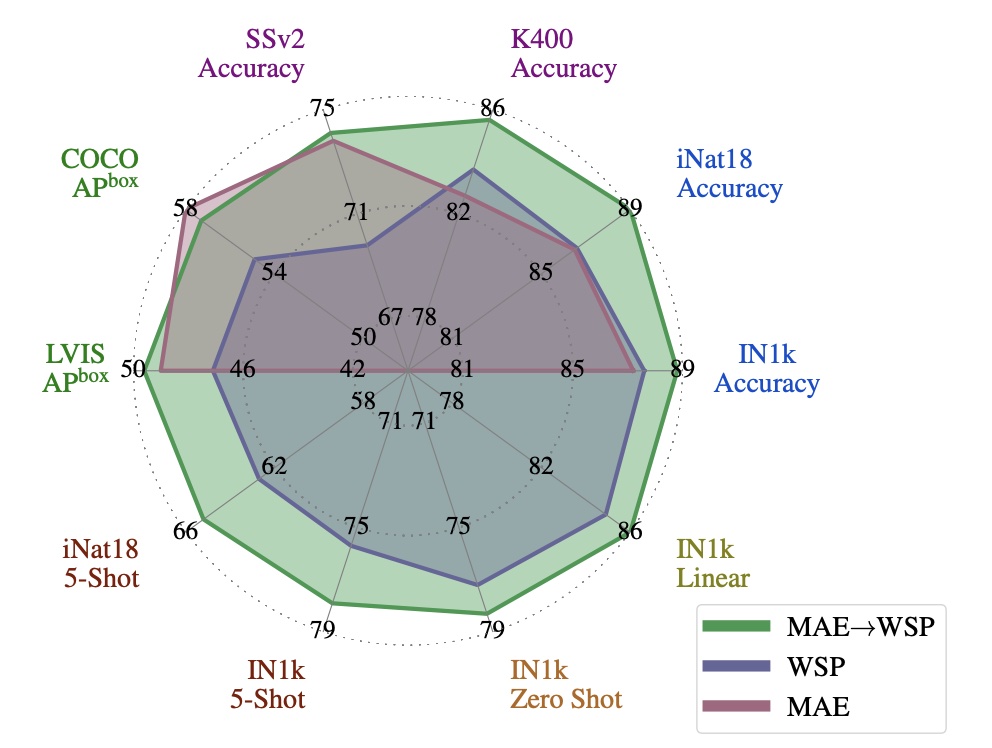
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mannat Singh *,
Quentin Duval *,
Kalyan Vasudev Alwala *,
Haoqi Fan ,
Vaibhav Aggarwal ,
Aaron Adcock ,
Armand Joulin ,
Piotr Dollár ,
Christoph Feichtenhofer ,
Ross Girshick ,
Rohit Girdhar ,
Ishan Misra
ICCV 2023
@inproceedings{singh2023effectiveness,
title={The effectiveness of MAE pre-pretraining for billion-scale pretraining},
author={Singh, Mannat and Duval, Quentin and Alwala, Kalyan Vasudev and Fan, Haoqi and Aggarwal, Vaibhav and Adcock, Aaron and Joulin, Armand and Doll{\'a}r, Piotr and Feichtenhofer, Christoph and Girshick, Ross and Girdhar, Rohit and Misra, Ishan},
booktitle={ICCV},
year={2023},
}
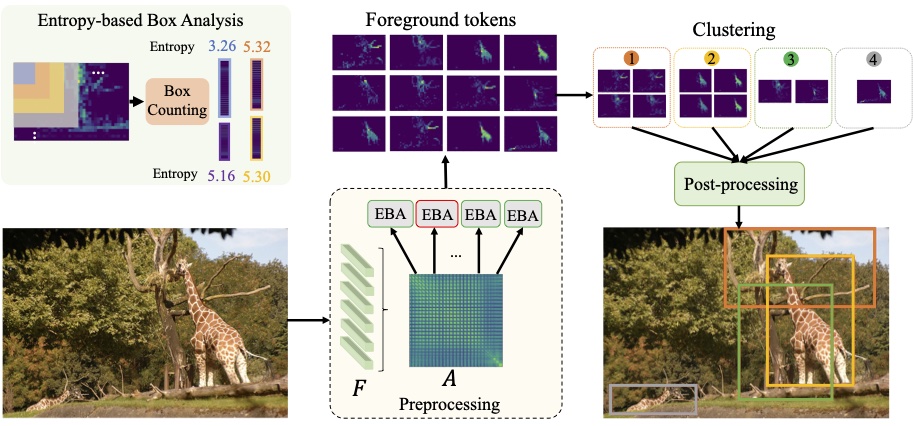
MOST: Multiple Object localization with Self-supervised Transformers for object discovery.
Sai Saketh Rambhatla ,
Ishan Misra
,
Rama Chellappa ,
Abhinav Shrivastava
ICCV 2023
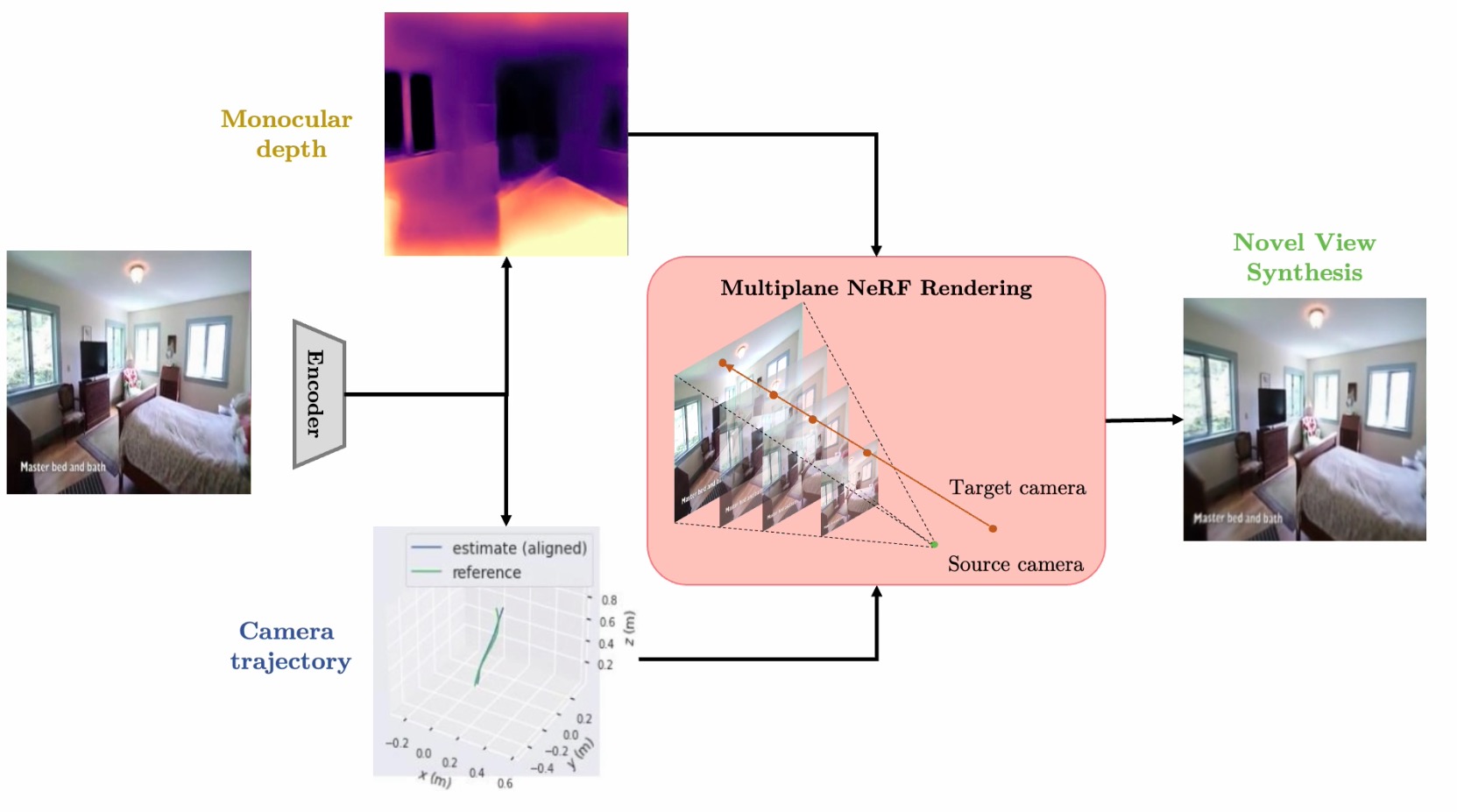
MonoNeRF: Learning Generalizable NeRFs from Monocular Videos without Camera Poses
Yang Fu ,
Ishan Misra
,
Xiaolong Wang
ICML 2023
ImageBind: One Embedding Space To Bind Them All
Rohit Girdhar *,
Alaaeldin El-Nouby *,
Zhuang Liu ,
Mannat Singh ,
Kalyan Vasudev Alwala ,
Armand Joulin ,
Ishan Misra
*
CVPR 2023
@inproceedings{girdhar2023imagebind,
title={ImageBind: One Embedding Space To Bind Them All},
author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2023},
}
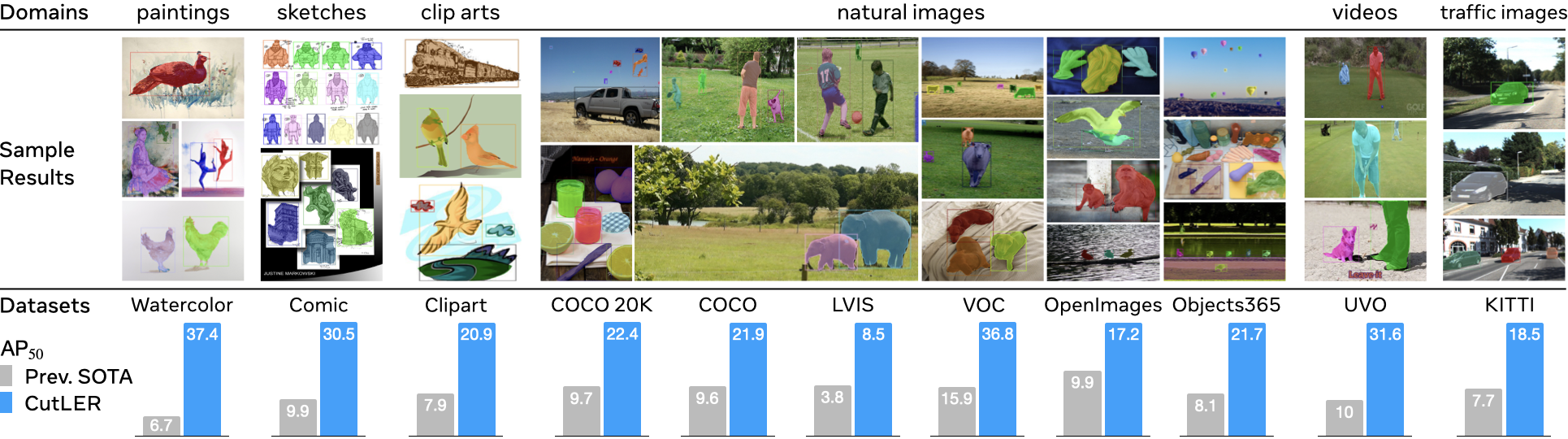
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
Xudong Wang ,
Rohit Girdhar ,
Stella X. Yu ,
Ishan Misra
CVPR 2023
@inproceedings{wang2023cut,
title={Cut and Learn for Unsupervised Object Detection and Instance Segmentation},
author={Wang, Xudong and Girdhar, Rohit and Yu, Stella X and Misra, Ishan},
booktitle={CVPR},
year={2023},
}
Learning Video Representations from Large Language Models
Yue Zhao ,
Ishan Misra
,
Philipp Krahenbuhl ,
Rohit Girdhar
CVPR 2023
@inproceedings{zhao2022lavila,
title={Learning Video Representations from Large Language Models},
author={Zhao, Yue and Misra, Ishan and Kr{\"a}henb{\"u}hl, Philipp and Girdhar, Rohit},
booktitle=CVPR,
year={2023},
}
The Hidden Uniform Cluster Prior in Self-Supervised Learning
Mahmoud Assran ,
Randall Balestriero ,
Quentin Duval ,
Florian Bordes ,
Ishan Misra
,
Piotr Bojanowski ,
Pascal Vincent ,
Michael Rabbat ,
Nicolas Ballas
ICLR 2023
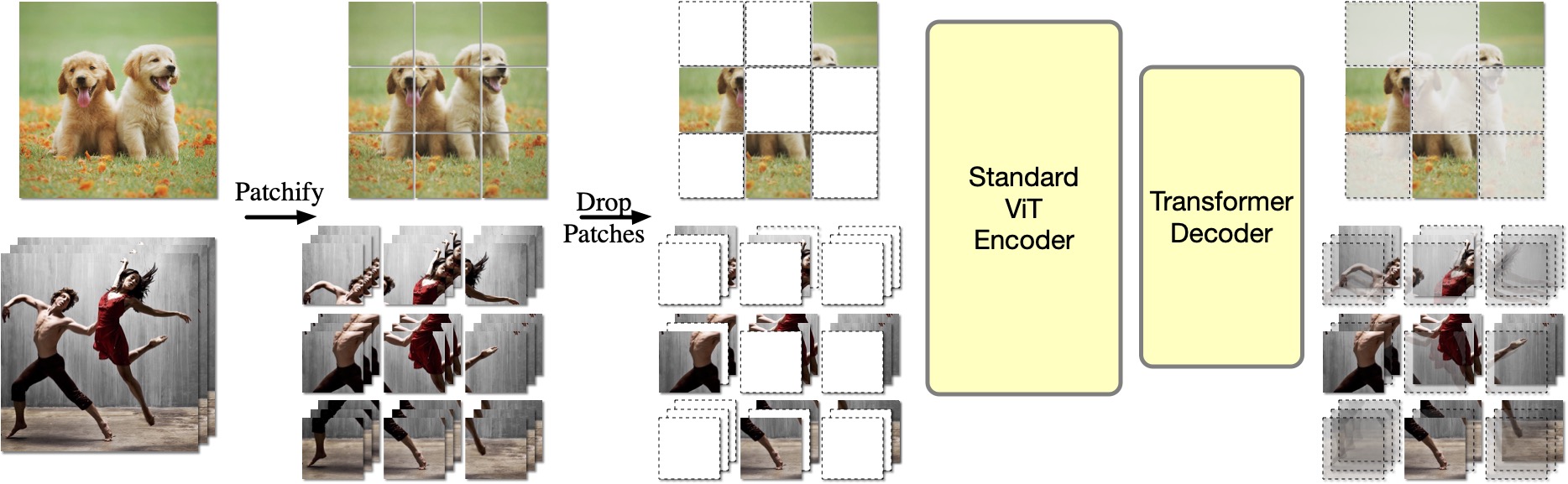
OmniMAE: Single Model Masked Pretraining on Images and Videos
Rohit Girdhar *,
Alaaeldin El-Nouby *,
Mannat Singh *,
Kalyan Vasudev Alwala *,
Armand Joulin ,
Ishan Misra
*
CVPR 2023
@inproceedings{girdhar2022omnimae,
title={OmniMAE: Single Model Masked Pretraining on Images and Videos},
author={Girdhar, Rohit and El-Nouby, Alaaeldin and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2023},
}
Masked Siamese Networks for Label-Efficient Learning
Mahmoud Assran ,
Mathilde Caron ,
Ishan Misra
,
Piotr Bojanowski ,
Florian Bordes ,
Pascal Vincent ,
Armand Joulin ,
Michael Rabbat ,
Nicolas Ballas
ECCV 2022
@inproceedings{assran2022masked,
title={Masked Siamese Networks for Label-Efficient Learning},
author={Assran, Mahmoud, and Caron, Mathilde, and Misra, Ishan, and Bojanowski, Piotr, and Bordes, Florian and Vincent, Pascal, and Joulin, Armand, and Rabbat, Michael, and Ballas, Nicolas},
booktitle={ECCV},
year={2022},
}
Detecting Twenty-thousand Classes using Image-level Supervision
Xingyi Zhou ,
Rohit Girdhar ,
Armand Joulin ,
Phillip Krahenbuhl ,
Ishan Misra
ECCV 2022
@inproceedings{zhou2021detecting,
title={Detecting Twenty-thousand Classes using Image-level Supervision},
author={Zhou, Xingyi and Girdhar, Rohit and Joulin, Armand and Kr{\"a}henb{\"u}hl, Philipp and Misra, Ishan},
booktitle={ECCV},
year={2022},
}
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Priya Goyal ,
Quentin Duval ,
Isaac Seessel ,
Mathilde Caron ,
Ishan Misra
,
Levent Sagun ,
Armand Joulin ,
Piotr Bojanowski
Arxiv 2022
Omnivore: A Single Model for Many Visual Modalities
Rohit Girdhar *,
Mannat Singh *,
Nikhila Ravi *,
Laurens van der Maaten ,
Armand Joulin ,
Ishan Misra
*
CVPR 2022
@inproceedings{girdhar2022omnivore,
title={{Omnivore: A Single Model for Many Visual Modalities}},
author={Girdhar, Rohit and Singh, Mannat and Ravi, Nikhila and van der Maaten, Laurens and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2022},
}
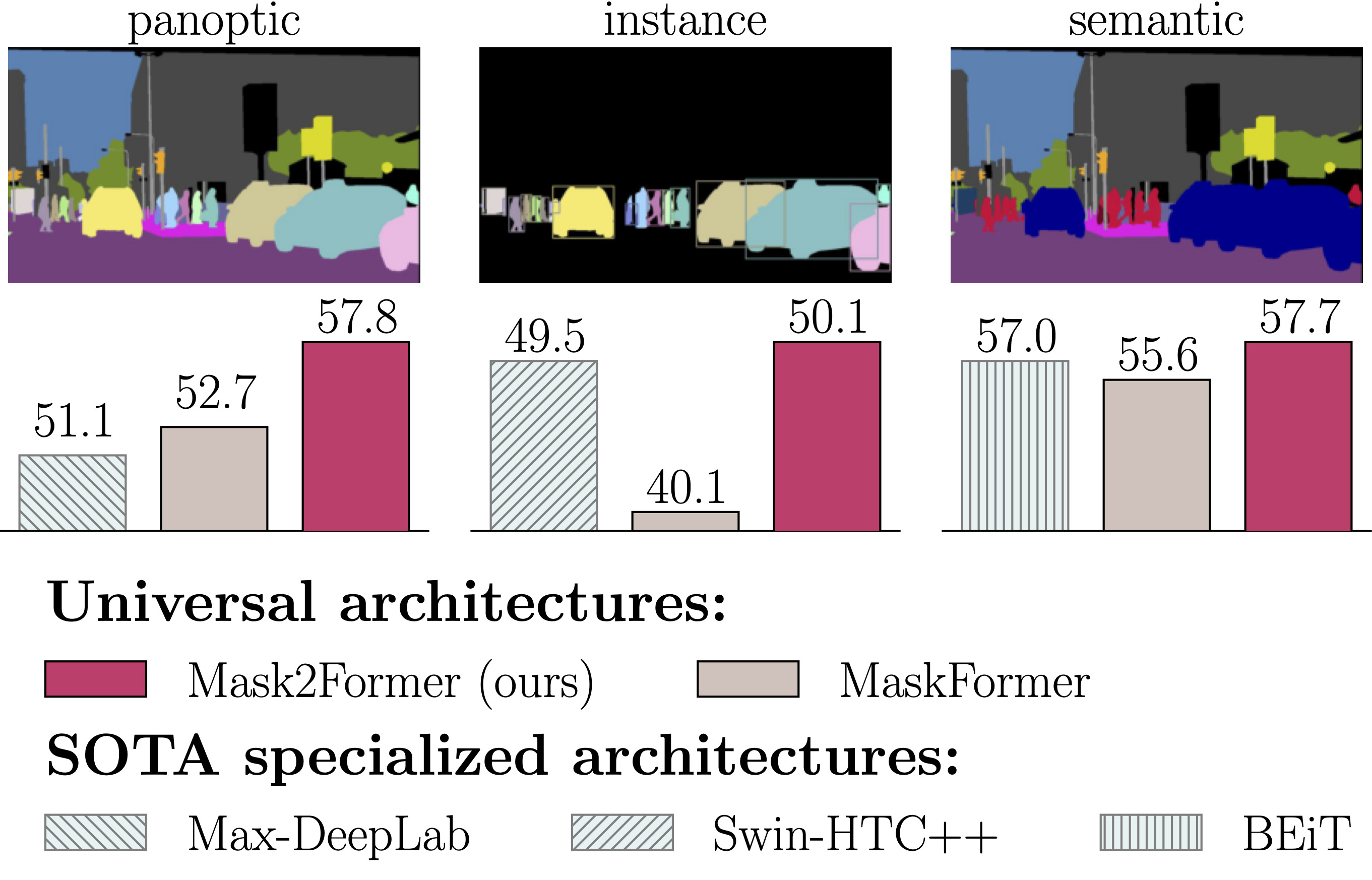
Masked-attention Mask Transformer for Universal Image Segmentation
Bowen Cheng ,
Ishan Misra
,
Alexander G. Schwing ,
Alexander Kirillov ,
Rohit Girdhar
CVPR 2022
An End-to-End Transformer Model for 3D Object Detection
Ishan Misra
,
Rohit Girdhar ,
Armand Joulin
ICCV 2021
@inproceedings{misra2021-3detr,
title={{An End-to-End Transformer Model for 3D Object Detection}},
author={Misra, Ishan and Girdhar, Rohit and Joulin, Armand},
booktitle={{ICCV}},
year={2021},
}
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron ,
Hugo Touvron ,
Ishan Misra
,
Hervé Jégou ,
Julien Mairal ,
Piotr Bojanowski ,
Armand Joulin
ICCV 2021
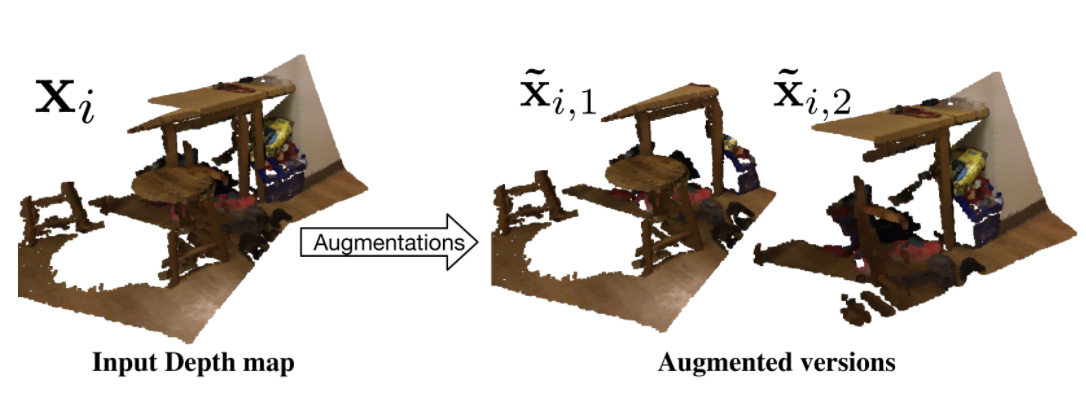
Self-Supervised Pretraining of 3D Features on any Point-Cloud
Zaiwei Zhang ,
Rohit Girdhar ,
Armand Joulin ,
Ishan Misra
ICCV 2021
@inproceedings{zhang_depth_contrast,
title={Self-Supervised Pretraining of 3D Features on any Point-Cloud},
author={Zhang, Zaiwei and Girdhar, Rohit and Joulin, Armand and Misra, Ishan},
journal={arXiv preprint arXiv:2101.02691},
year={2021},
}
MDETR : Modulated Detection for End-to-End Multi-Modal Understanding
Aishwarya Kamath ,
Mannat Singh ,
Yann LeCun ,
Ishan Misra
,
Gabriel Synnaeve ,
Nicolas Carion
ICCV 2021
Audio-Visual Instance Discrimination with Cross-Modal Agreement
Pedro Morgado ,
Nuno Vasconcelos ,
Ishan Misra
CVPR 2021
Robust Audio-Visual Instance Discrimination
Pedro Morgado ,
Ishan Misra
,
Nuno Vasconcelos
CVPR 2021
@ InProceedings{morgado2021_robust_xid,
title={Robust Audio-Visual Instance Discrimination},
author={Pedro Morgado, Ishan Misra, Nuno Vasconcelos},
booktitle = {{CVPR}},
year={2021},
}
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Jure Zbontar *,
Li Jing *,
Ishan Misra
,
Yann LeCun ,
Stéphane Deny
ICML 2021
@inproceedings{zbontar_barlowtwins,
title={Barlow Twins: Self-Supervised Learning via Redundancy Reduction},
author={Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, Stephane Deny},
booktitle={ICML},
year={2021},
}
3D Spatial Recognition without Spatially Labeled 3D
Zhongzheng Ren ,
Ishan Misra
,
Alexander G. Schwing ,
Rohit Girdhar
CVPR 2021
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
Mathilde Caron ,
Ishan Misra
,
Julien Mairal ,
Priya Goyal ,
Piotr Bojanowski ,
Armand Joulin
NeurIPS 2020
@inproceedings{caron2020swav,
title={Unsupervised Learning of Visual Features by Contrasting Cluster Assignments},
author={Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin},
year={2020},
booktitle={NeurIPS},
}
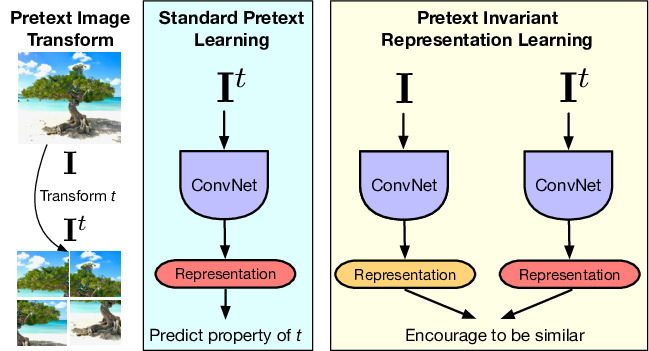
Self-Supervised Learning of Pretext-Invariant Representations
Ishan Misra
,
Laurens van der Maaten
CVPR 2020
@inproceedings{misra2020pirl,
title={Self-Supervised Learning of Pretext-Invariant Representations},
author={Misra, Ishan and van der Maaten, Laurens},
booktitle={CVPR},
year={2020},
}
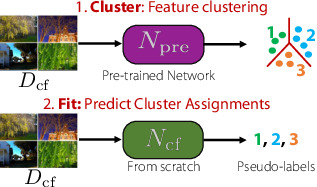
ClusterFit: Improving Generalization of Visual Representations
Xueting Yan *,
Ishan Misra
*,
Abhinav Gupta ,
Deepti Ghadiyaram *,
Dhruv Mahajan *
CVPR 2020
@inproceedings{yan2020cluster,
title={{ClusterFit: Improving Generalization of Visual Representations}},
author={Xueting Yan, Ishan Misra, Abhinav Gupta, Deepti Ghadiyaram, Dhruv Mahajan},
booktitle={CVPR},
year={2020},
}
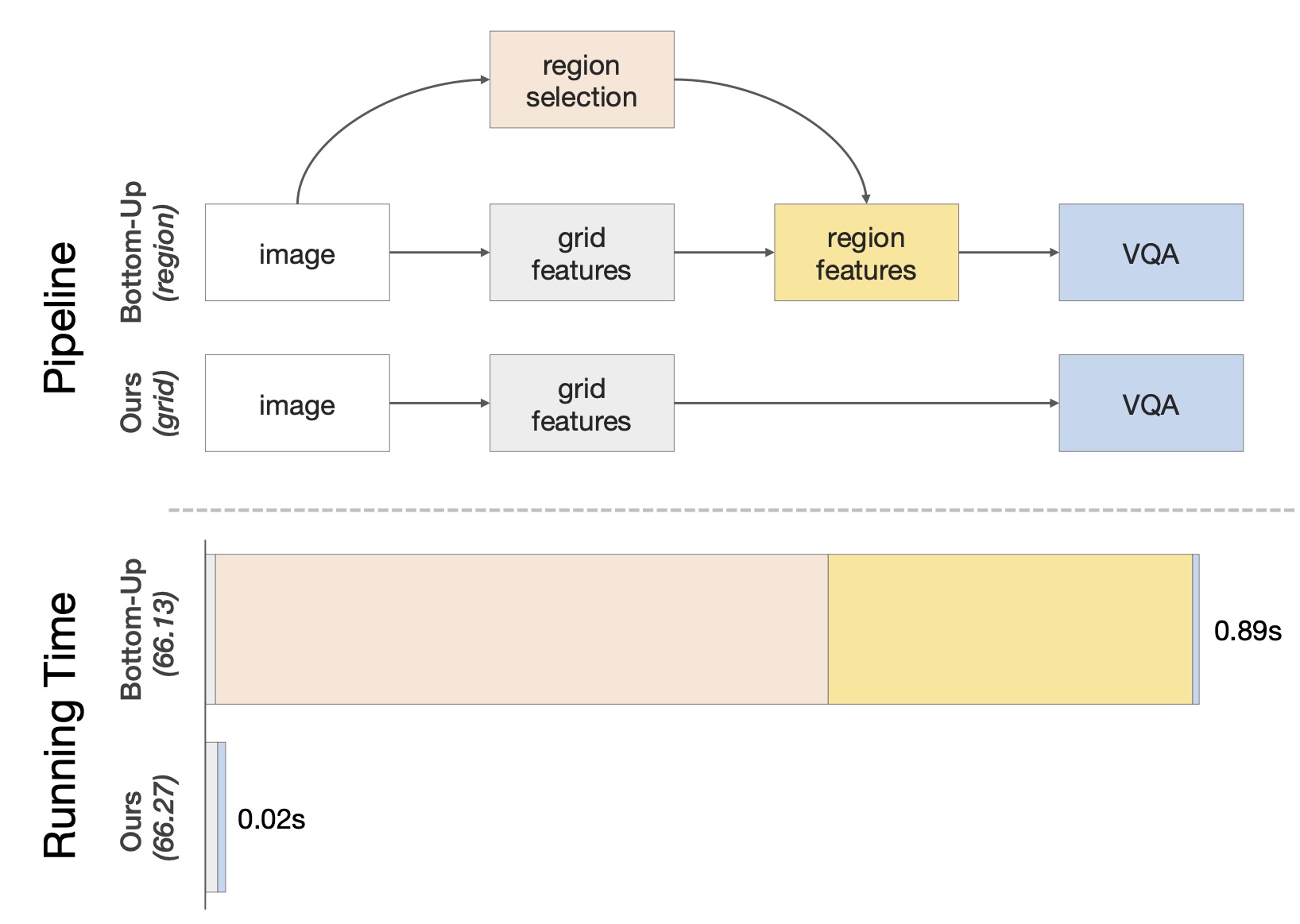
In Defense of Grid Features for Visual Question Answering
Huaizu Jiang ,
Ishan Misra
,
Marcus Rohrbach ,
Erik Learned-Miller ,
Xinlei Chen
CVPR 2020
@inproceedings{jiang2020grid,
title={In Defense of Grid Features for Visual Question Answering},
author={Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, Xinlei Chen},
booktitle={CVPR},
year={2020},
}
3D-RelNet: Joint Object and Relational Network for 3D Prediction
Nilesh Kulkarni ,
Ishan Misra
,
Shubham Tulsiani ,
Abhinav Gupta
ICCV 2019
Scaling and Benchmarking Self-Supervised Visual Representation Learning
Priya Goyal ,
Dhruv Mahajan ,
Abhinav Gupta *,
Ishan Misra
*
ICCV 2019
Binary Image Selection (BISON): Interpretable Evaluation of Visual Grounding
Hexiang Hu ,
Ishan Misra
,
Laurens van der Maaten
ICCV Workshop on Vision and Language 2019
@article{hexiang2018bison,
title={{Binary Image Selection (BISON): Interpretable Evaluation of Visual Grounding}},
author={Hu, Hexiang and Misra, Ishan and van der Maaten, Laurens},
journal={arXiv preprint arXiv:1901.06595},
year={2019},
}
Does Object Recognition Work for Everyone?
Terrance DeVries *,
Ishan Misra
*,
Changhan Wang *,
Laurens van der Maaten
CVPR 2019
Mainstream: Dynamic Stem-Sharing for Multi-Tenant Video Processing
Angela Jiang ,
Daniel L.-K. Wong ,
Christopher Canel ,
Ishan Misra
,
Michael Kaminsky ,
Michael Kozuch ,
Padmanabhan Pillai ,
David G. Andersen and Gregory Ganger
USENIX Annual Technical Conference 2018
@inproceedings {jiangmainstream18,
title = {Mainstream: Dynamic Stem-Sharing for Multi-Tenant Video Processing},
authors = {Angela Jiang and Daniel L.-K. Wong and Christopher Canel and Ishan Misra and Michael Kaminsky and Michael Kozuch and Padmanabhan Pillai and David G. Andersen and Gregory Ganger},
booktitle = {{USENIX} Annual Technical Conference ({USENIX} {ATC} 18)},
year = {2018},
address = {Boston, MA},
url = {https://www.usenix.org/conference/atc18/presentation/jiang},
publisher = {{USENIX} Association},
}
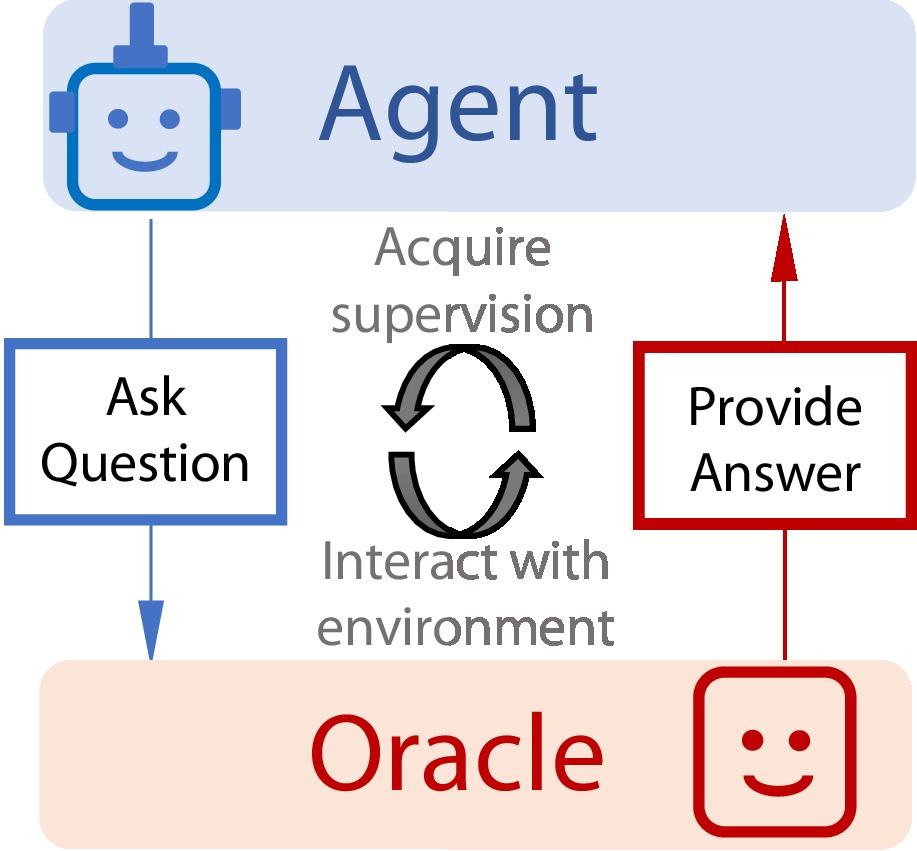
Learning by Asking Questions
Ishan Misra
,
Ross Girshick ,
Rob Fergus ,
Martial Hebert ,
Abhinav Gupta ,
Laurens van der Maaten
CVPR 2018
@inproceedings{misra2017lba,
Author = {Ishan Misra and Ross Girshick and Rob Fergus and,
Martial Hebert and Abhinav Gupta and Laurens van der Maaten},
Title = {{Learning by Asking Questions}},
Booktitle = {{CVPR}},
Year = {2018},
}
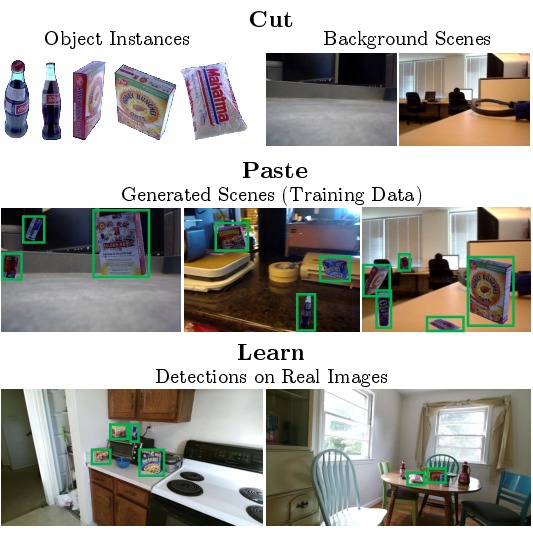
Cut Paste and Learn: Surprisingly Easy Synthesis
for Instance Detection
Debidatta Dwibedi ,
Ishan Misra
,
Martial Hebert
ICCV 2017
@inproceedings{debi2017cutpaste,
title={{Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection}},
author={Dwibedi, Debidatta and Misra, Ishan and Hebert, Martial},
booktitle={ICCV},
year={2017},
}
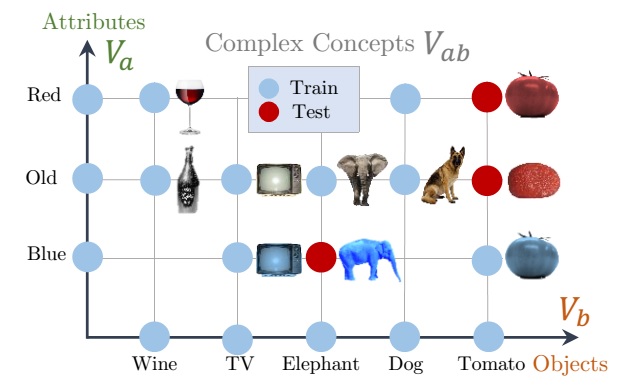
From Red Wine to Red Tomato: Composition with Context
Ishan Misra
,
Abhinav Gupta ,
Martial Hebert
CVPR 2017
@inproceedings{misra2017composing,
title={{From Red Wine to Red Tomato: Composition with Context}},
author={Misra, Ishan and Gupta, Abhinav and Hebert, Martial},
booktitle={CVPR},
year={2017},
}
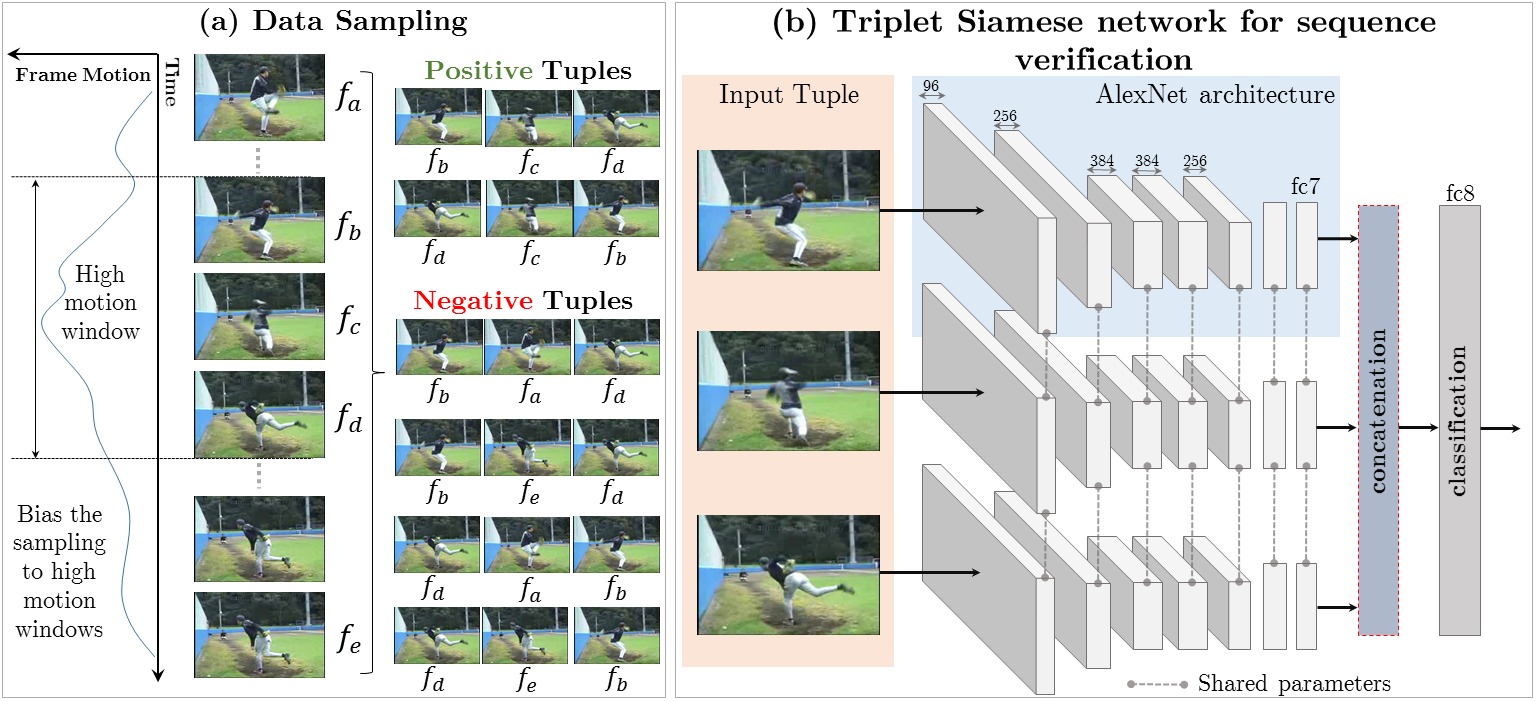
Shuffle and Learn: Unsupervised Learning
using Temporal Order Verification
Ishan Misra
,
C. Lawrence Zitnick ,
Martial Hebert
ECCV 2016
@inproceedings{misra2016unsupervised,
title={{Shuffle and Learn: Unsupervised Learning using Temporal Order Verification}},
author={Misra, Ishan and Zitnick, C. Lawrence and Hebert, Martial},
booktitle={ECCV},
year={2016},
}
Seeing through the Human Reporting Bias:
Visual Classifiers from Noisy
Ishan Misra
,
C. Lawrence Zitnick ,
Margaret Mitchell ,
Ross Girshick
CVPR 2016
@inproceedings{MisraNoisy16,
Author = {Ishan Misra and C. Lawrence Zitnick and Margaret Mitchell and Ross Girshick},
Booktitle = {CVPR},
Title = {{Seeing through the Human Reporting Bias: Visual Classifiers from Noisy Human-Centric Labels}},
Year = {2016},
}
,
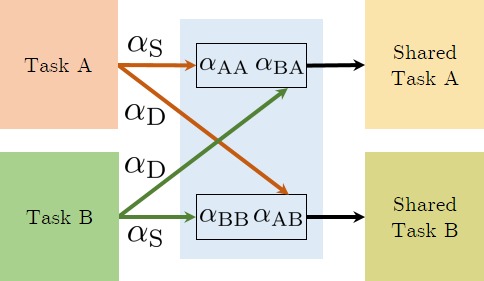
Cross-stitch Networks for Multi-Task Learning
Ishan Misra
*,
Abhinav Shrivastava *,
Abhinav Gupta ,
Martial Hebert
CVPR 2016
PDF
BibTeX
Spotlight
*Authors contributed equally
@inproceedings{MisraCrossMTL16,
Author = {Ishan Misra and Abhinav Shrivastava and Abhinav Gupta and Martial Hebert},
Booktitle = {CVPR},
Title = {{Cross-stitch Networks for Multi-task Learning}},
Year = {2016},
}
,
Generating Natural Questions About an Image
Nasrin Mostafazadeh ,
Ishan Misra
,
Jacob Devlin ,
Margaret Mitchell ,
Xiaodong He ,
Lucy Vanderwende
ACL 2016
@article{mostafazadeh2016generating,
title={Generating Natural Questions About an Image},
author={Mostafazadeh, Nasrin and Misra, Ishan and Devlin, Jacob and Mitchell, Margaret and He, Xiaodong and Vanderwende, Lucy},
journal={arXiv preprint arXiv:1603.06059},
year={2016},
}
,
Visual Storytelling
Ting-Hao Huang ,
Francis Ferraro ,
Nasrin Mostafazadeh ,
Ishan Misra
,
Jacob Devlin ,
Aishwarya Agrawal ,
Ross Girshick ,
Xiaodong He ,
Pushmeet Kohli ,
et al.
NAACL 2016
@article{ferraro2016visual,
title={Visual storytelling},
author={Ferraro, Francis and Mostafazadeh, Nasrin and Misra, Ishan and Agrawal, Aishwarya and Devlin, Jacob and Girshick, Ross and He, Xiaodong and Kohli, Pushmeet and Batra, Dhruv and Zitnick, C Lawrence and Parikh, Devi and Vanderwende, Lucy and Galley, Michel and Mitchell, Margaret},
journal={arXiv preprint arXiv:1604.03968},
year={2016},
}
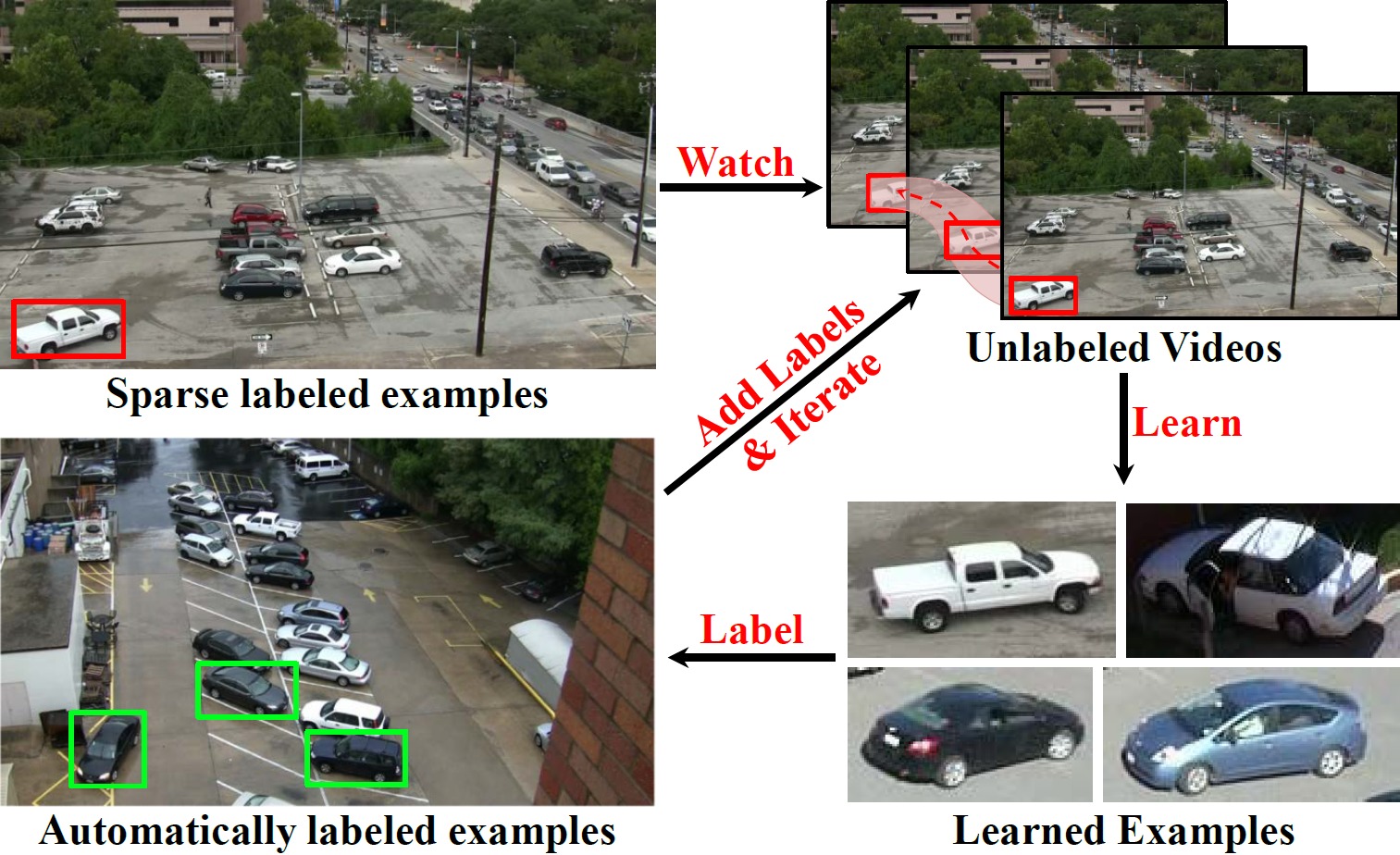
Watch and Learn: Semi-Supervised Learning of Object Detectors from Video
Ishan Misra
,
Abhinav Shrivastava ,
Martial Hebert
CVPR 2015
@inproceedings{MisraSSL15,
Author = {Ishan Misra and Abhinav Shrivastava and Martial Hebert},
Booktitle = {CVPR},
Title = {Watch and Learn: Semi-Supervised Learning of Object Detectors from Videos},
Year = {2015},
}
,
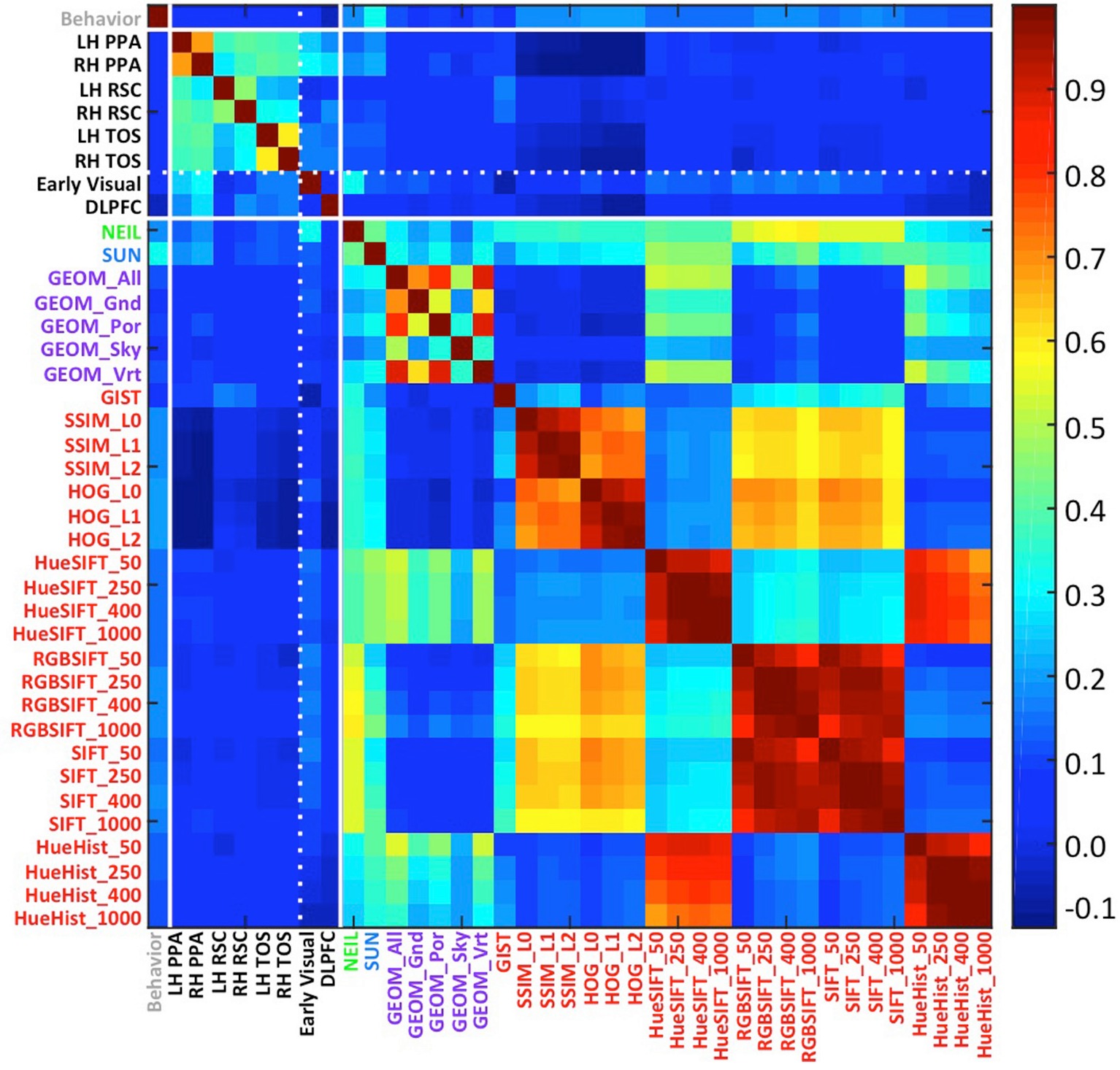
Applying artificial vision models to human scene understanding
Elissa Aminoff ,
M. Toneva ,
Abhinav Shrivastava ,
Xinlei Chen ,
Ishan Misra
,
et al.
Journal of Frontiers in Computational Neuroscience 2015
Data-driven Exemplar Model Selection
Ishan Misra
,
Abhinav Shrivastava ,
Martial Hebert
WACV 2014
@inproceedings{MisraExemplarSelection,
Author = {Ishan Misra and Abhinav Shrivastava and Martial Hebert},
Booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)},
Title = {Data-driven Exemplar Model Selection},
Year = {2014},
}
,